Non esiste attività umana, oggi, che non abbia una qualche forma di intermediazione digitale, e lo stesso si può dire di moltissimi “oggetti”. Come risultato abbiamo un mondo parallelo che contiene un incredibile numero di tracce digitali. Sono i famosi Big Data, parola d’ordine che identifica l’enorme volume di dati, strutturati e non strutturati, disponibile in questo mondo parallelo: una straordinaria fonte di informazioni su una vasta gamma di argomenti: dalle preferenze dei partecipanti alle loro attività, dai loro comportamenti al valore che essi danno a ciò che viene loro offerto.
La produzione di articoli, libri, ricerche ecc. sul tema è incredibile. E altrettanto incredibile è una certa confusione su come e quando utilizzare queste fonti e soprattutto su quali informazioni riescono a fornire. E’ sorprendente vedere come un fenomeno, un tempo considerato generatore di disorientamento e confusione, il cosiddetto sovraccarico informativo (information overload), una volta cambiato nome in Big Data sia visto come panacea, in grado di fornire una vasta gamma di indicazioni utili o essenziali su molti aspetti della vita moderna di individui, organizzazioni e mercati.
I Big Data sono sicuramente un’opportunità, ma è difficile coglierla appieno, ed evitare abbagli ed equivoci, se non se ne conoscono bene gli aspetti tecnici, umani e sociali.
L’attrazione di questo mondo è così forte che qualcuno comincia già a parlare di nuovo paradigma e a sostenere che il “vecchio” metodo scientifico di indagine può andare in pensione sostituito da sofisticati metodi di machine learning in grado di identificare pattern e correlazioni consentendoci di capire qualunque fenomeno. Forse però ci si dimentica che, come sosteneva Ronald Coase (Nobel per l’Economia): “Se torturate abbastanza i dati, alla fine confesseranno”. E ci si dimentica che, banalmente, in un vastissimo insieme di dati, la probabilità di trovare correlazioni significative, ancorché spurie o irrilevanti, può arrivar al 98% (lo dice bene Vincent Granville: http://www.analyticbridge.com/profiles/blogs/the-curse-of-big-data). Se volete divertirvi guardate qui: http://www.tylervigen.com/, dove potete sperimentare gli accoppiamenti più assurdi, ma perfettamente giustificati dal punto di vista statistico. Un esempio:
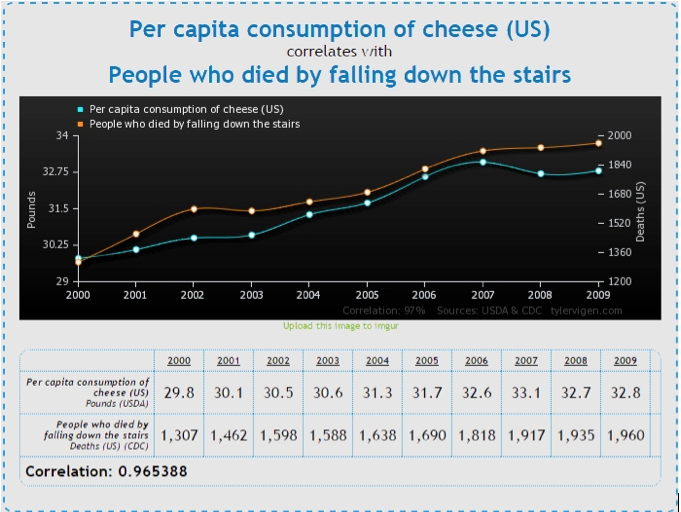
La capacità di evidenziare fenomeni complessi combinando tutte le fonti di informazioni disponibili è un vantaggio enorme per chi è in grado di sfruttare fino in fondo le opportunità oggi disponibili. Tuttavia, al di là della sovresposizione commerciale, un’analisi più attenta e neutra del fenomeno Big Data mette in evidenza una serie di problemi, alcuni dei quali sono ben noti in ambito accademico, ma potrebbero non essere pienamente familiari agli operatori del settore. Come ha detto Mitchell Kapor “recuperare informazioni da Internet è come bere da un idrante”.
Molte rivendicazioni di obiettività e precisione possono essere fuorvianti, i grandi insiemi di dati provenienti da fonti online sono spesso poco attendibili e instabili, e questa loro dinamicità impedisce di fatto i tentativi di replicare uno studio per verificarne i risultati. Inoltre, errori e lacune possono essere amplificate quando più insiemi di dati vengono utilizzati simultaneamente. Le grandi quantità di dati disponibili, poi, mettono a dura prova i nostri metodi convenzionali di analisi. In assenza di un obiettivo di ricerca molto chiaro e un altrettanto rigoroso programma di raccolta dati, il rischio di scoprire effetti insignificanti o risultati ingannevoli è piuttosto elevato. Un esempio è la recente revisione dell’indicatore di Google sull’influenza, che è stato contaminato da una serie di fattori estranei (vedi http://bits.blogs.nytimes.com/2014/03/28/google-flu-trends-the-limits-of-big-data/).
Grandi quantità di dati hanno bisogno di una riconsiderazione dei metodi utilizzati per l’analisi, a maggior ragione quando il problema richiede la valutazione (automatica) di elementi non strutturati come testi o immagini. Qui le difficoltà aumentano e la necessità di metodologie rigorose e verificabili, integrate da attente validazioni dei risultati, diventa ineludibile.
Il primo punto importante è, come noto (o dovrebbe), una chiara definizione degli obiettivi, il secondo, diretta conseguenza, la decisione sui metodi da utilizzare per la raccolta e il trattamento dei dati necessari. La raccolta di tweet, post su Facebook, recensioni o simili può essere un compito piuttosto complicato, e richiede strumenti e competenze non proprio alla portata di tutti, anche se si cominciano e vedere proposte “usabili” anche in ambienti non iperstrutturati o iperdimensionati (vedi per esempio: http://www.iby.it/turismo/papers/rb-enter2015-RasPi.pdf).
Ma, una volta adottato metodologie corrette e verificate rigorosamente, è di fondamentale importanza cominciare ad avvalersi delle possibilità offerte. Infatti, e qualche segnale è già evidente, le differenze create fra chi riesce a superare le difficoltà d’accesso ai nuovi dati e ad avere le risorse necessarie per un loro pieno utilizzo, e chi invece non può avvalersi delle indicazioni derivabili da tali studi, rischiano di produrre un nuovo tipo di divario digitale.

Ci sono pochi dubbi sul fatto che avere accesso a una grande quantità di dati, che coprono praticamente ogni aspetto della vita umana (e non solo), sia un beneficio incredibile, ma ottenere questi vantaggi richiede grande cura. E, come appare sempre più evidente, le “vecchie” tecniche di studio e di indagine non affatto obsolete, conservano tutta la loro validità (vedi: http://bits.blogs.nytimes.com/2014/10/31/the-new-thing-in-google-flu-trends-is-traditional-data/).
Piuttosto, sarebbe necessaria una riflessione approfondita su come combinare in maniera corretta i due mondi e far sì che nuovi e vecchi dati possano dare un contributo efficace alla soluzione dei nostri problemi. Senza dimenticare, poi, che i risultati di queste elaborazioni vanno interpretati e adattati alle situazioni specifiche. Qui, checché se ne possa pensare, non esistono ricette pronte e facili da mettere in campo, ma solo faticoso lavoro di studio, di ricerca e di sperimentazione.

Solo così potremo convincere i nuovi dati a confessare.
Buon Natale e felice anno nuovo!!!